| visual | word | ton | home | links | open museum skryl |
| XII. SYSTEM DES GENETISCHEN CODES |
|
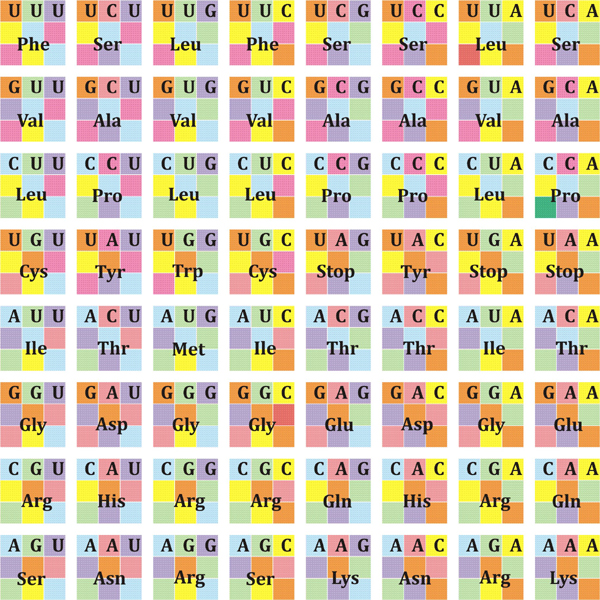
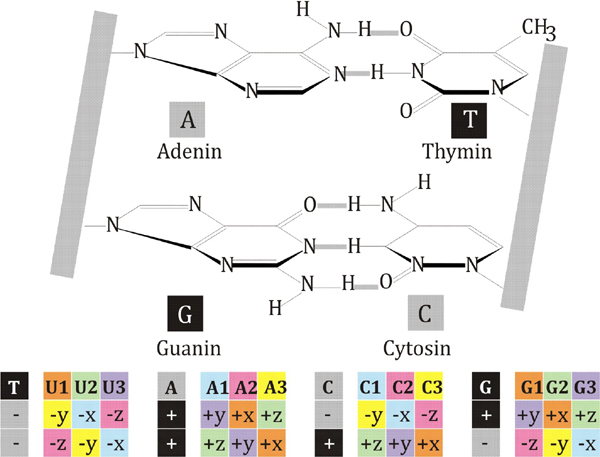
Der genetische Code ist ein Ergebnis physikalischer Bedingungen, in denen sich Organismen im Verlauf ihrer gesamten Evolution befanden. Die Informationen über diese Bedingungen stellen sich dar als Verfahren der Bildung komplexer Strukturen des Organismus aus den Kohlenstoff-, Wasserstoff-, Sauerstoff-Atomen und anderen Elementen. Die Atome der Stoffe bilden anorganische Moleküle, welche sich dann zu komplizierten organischen Molekülen ordnen - Eiweiße, Fette, Kohlenhydrate. Aus diesen Molekülen sind die Organismen aufgebaut. Dieser Bauplan heißt genetischer Code. Der genetische Code ist universell für alle lebenden Organismen. Dieses von allen Organismen geteilte gemeinsame Grundprinzip der Codierung wird als «Universalität des Codes» bezeichnet. Es erklärt sich aus der Evolution so, dass der genetische Code schon sehr früh in der Entwicklungsgeschichte des Lebens ausgestaltet und dann von allen sich entwickelnden Arten weitergegeben wurde. Eine solche Generalisierung schließt nicht aus, dass sich die Häufigkeit verschiedener Codewörter zwischen den Organismen unterscheiden kann. Biologische Information ist in den Genabschnitten des DNA-Moleküls codiert. Bis heute wurde der genetische Code noch nicht als System dargestellt. Mithilfe der vorgeschlagenen Matrix können Sie den genetischen Code systematisieren. Wir schlagen ein System des genetischen Codes vor (Abb. 43). Der genetische Code besteht aus 64 Kombinationen von vier Nukleotiden: Adenin-A, Guanin-G, Cytosin-C, Uracil-U (in RNA) oder Thymin-T (in DNA). Die Realisierung von genetischer Information in lebenden Zellen wird mittels zweier Matrixprozesse durchgeführt: Transkription (d.h. Synthese von m-RNA auf einer DNA-Matrize) und Translation eines genetischen Codes in eine Aminosäuresequenz (Synthese einer Polypeptidkette auf m-RNA). Die 20 Aminosäuren in der Natur entsprechen 64 Triplett-Codons. Abk.: Ala – Alanin; Arg – Arginin; Asn – Asparagin; Asp – Asparaginsäure; Val – Valin; His – Histidin; Gly – Glycin; Gln – Glutamin; Glu – Glutaminsäure; Ile – Isoleucin; Leu – Leucin; Lys – Lysin; Met – Methionin; Pro – Prolin; Ser – Serin; Tyr – Tyrosin; Thr – Threonin; Trp – Tryptophan; Phe – Phenylalanin; Cys – Cystein. Die drei Codons UAA, UGA, UAG bilden keine Aminosäuren und bestimmen das Ende der Polypeptidkette (Term). Das AUG-Codon bestimmt den Beginn der Synthese. Die chemischen Strukturen der Pyrimidinbasen von Cytosin C und Uracil U (Thymin) bestehen aus einem einzigen hexagonalen Ring. Die chemischen Strukturen der Purinbasen von Adenin A und Guanin G bestehen aus zwei Ringen - sechseckig und fünfeckig. Im DNA-Molekül sind zwei Basen durch Wasserstoffbrücken verbunden: Zwei Wasserstoffbrvcken bilden U-A und drei bilden C-G. Vier Varianten der Koordinatenkombination in der Matrix entsprechen vier Nukleotiden. Die Reihenfolge der Nukleotidverteilung im Codon entspricht einer Kombination von Koordinaten. (Abb.44)
|